Deploying (safely) to production, the AWS way
How safe are are our deployments, really?
→→→ A little prompt toward good practice…
I recently stumbled across a genuinely good article from the Amazon Builders Library on Automating safe, hands-off deployments.
Some key insights
- Amazon takes their microservice decoupling seriously. The “independently deployable” aspect means that they use multiple pipelines per microservice, but each microservice’s processes are fully decoupled.
- Code review is a real thing… but it’s definitely not abitrary or ad hoc – it might involve explict questions around testing (practices and coverage), monitoring and observability, and rollout practices (e.g. can this be safely merged and deployed? have all dependencies already been deployed? does this support safe rollback?)
- Teams do real build/unit tests with all dependent services mocked/stubbed.
- Multiple pre-prod environments are used
- Alpha/beta are more isolated using all non-prod environments to run functional & integration tests, basic health checks
- Gamma environments are as close to prod as possible – even using canary-like methods – and are usually multi-region
- Integration tests use real dependencies (no mocks/stubs). An implication of the point above about service decoupling is that if these are within the service they likely hit other non-prod services… but should likely be hitting actual/prod services for anything else (e.g. S3)
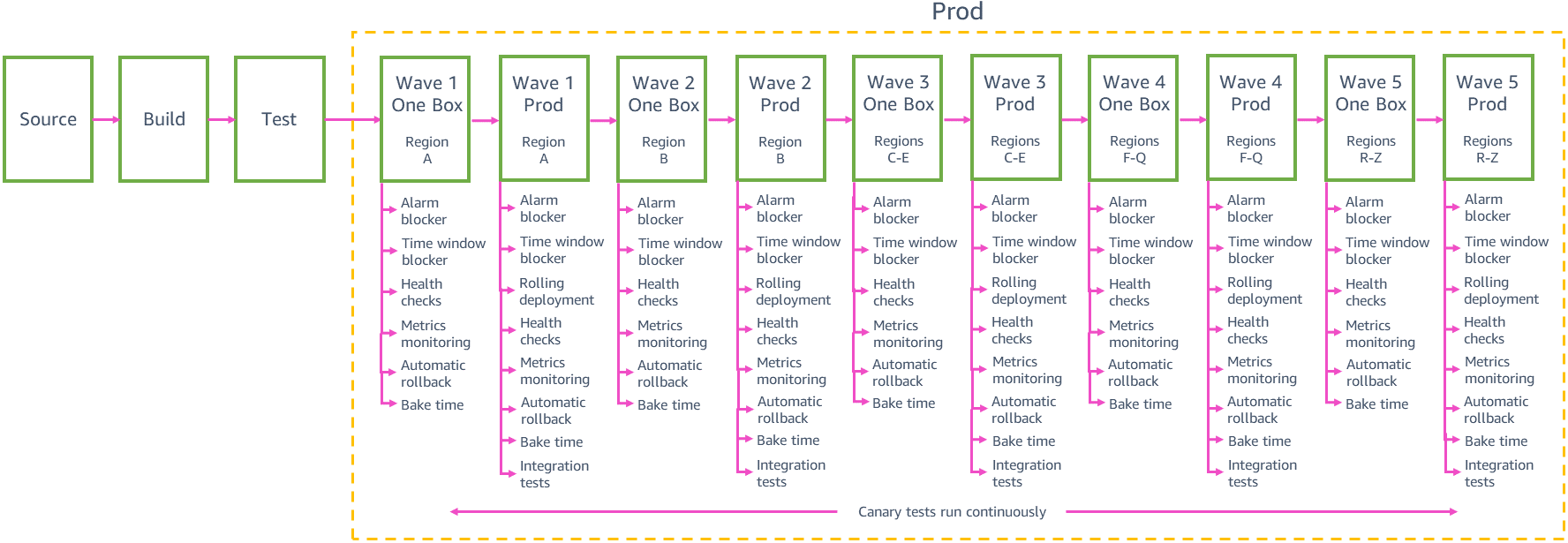
- They’re serious about limiting the blast radius of the change in terms of AZs and Regions - “Our #1 objective for production deployments at AWS is to prevent negative impact to multiple Regions at the same time and to multiple Availability Zones in the same Region.”
 Source:
Source: - At each step in the above (from the canary/one-box onward) the process is automated and waits for success. At most the one-box has 10% of requests.
- The whole thing is therefore fully automated, with special alarms testing a whole stack of metrics (fault rate, latency, CPU, memory usage, disk usage, etc)
- The deployment incorporates the concept of “bake time”, recognising that some issues are more of a slow burn, taking a while to surface. The approach therefore begins by rolling out more slowly (e.g. one hour for first region), accelerating as confidence grows. To address situations where the service might be quiet, particular usage thresholds might need to be reached (e.g. 10K API calls) rather than a time-based measure.